On deploying a neural net to AWS Lambda
Week 5 at Recurse Center
Week 5 at Recurse Center
I’m heading into my last week at Recurse, and feeling an excited rush to wrap up the MIDI archive project I began ruminating on the previous week. The shape of it has been slowly coming together, and what remains to be seen is how much I can manage to deploy in the handful of days I have left. At the moment, the project looks something like the following, involving many components beyond just neural net model.
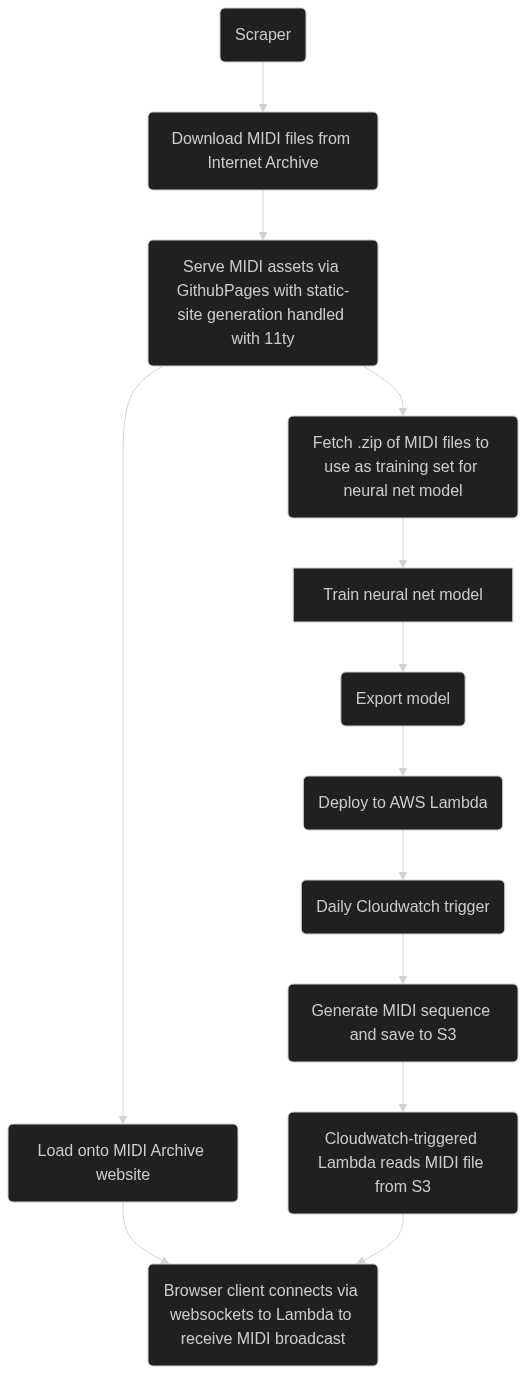
Since the details of this loose architecture diagram are subject to change, I’ll focus on it more in my next post, and instead would like to reflect more on the AWS Lambda portion of the diagram.
I’m not yet sure if this project is something I’ll keep working on, or if I’ll let it stay in some form as a proof of concept, but I’d like to deploy in a low-cost and low-maintenance way that would allow me to let it passively exist online with minimal billing and upkeep. While there’s lots of options to deploy ML models to production, I set my sights on Lambda early on because of its usage-based pricing model where I can have the service turned off from most of the day. The model I’ve built so far has pretty limited utility, certainly not sophisticated enough to be useful for generating actual music or aiding the process of composing, so there’s little to warrant it having very much server uptime.
But this limitation also feels ripe for some creative elaboration, and I’ve been circling around the idea of having the ML model present daily “performances”, in which visitors to the site can hear some music generated by the model. The general inspiration of this comes from Low Tech Magazine, which is hosted on a solar-powered server that sometimes goes down if the weather is cloudy for too long and the battery depletes. Or Radio Amnion, which only broadcasts for a few days around each new moon. There’s something beautiful about these websites that have variable behavior depending on time or atmospheric conditions.
As for right now, the plan is to have two separate Lambda functions, each of which is only invoked once a day. The first is responsible for serving the machine learning model, and will generate a MIDI sequence that is stored in S3. The second is then responsible for broadcasting that MIDI file over websockets to visitors to the site. Lambdas have a maximum execution time of 15 minutes, which will also limit the duration of the broadcast. An important detail of this, too, is that all visitors to the site will experience the same broadcast at the same time, which to me makes it more of a “performance” than just letting visitors play the MIDI file as they please.
In terms of implementation, I’ve been struggling to get the model hosted in Lambda, as I hadn’t quite realized how beefy the PyTorch library is, which I’ve been using to build and train the model, and is far too large for Lambda’s filesize limitations. At first I tried to use an existing tool called torchlambda to minimize and deploy my trained model, but should have taken the fact that it hadn’t been updated in three years as a red flag. In that time, PyTorch has gone through a major version change, and made torchlambda rather unsuitable.
At the same time, it was interesting to me that torchlambda used something called torchscript to compile a model to C++, and vastly minimize the size of source code and dependencies to be deployed to Lambda. But as I was considering going further down this path, Kenny, a fellow Recurse resident suggested that I look into https://onnx.ai/, which aims to bring interoperability to the growing ecosystem of various ML libraries and runtime environments. The Onnx runtime, unlikely PyTorch, is relatively small (~45 MB), and falls within Lambda’s filesize restrictions. After a quick test run, loosely following suggestions here, I’ve set up a toy model deployed to Lambda using the Onnx runtime packaged into a Lambda layer, and happy to report that it’s functioning as expected!