Reflections on my time at Recurse Center
(Note: this writing has also been published to Medium here)
This past autumn, I spent a six-week residency at Recurse Center, a retreat where “curious programmers recharge and grow.“ Earlier that year, I had left my post at Vox Media as an engineering manager, and in the intervening months, had been exploring the world of ideas and software, as if anew. Accordingly, I arrived at Recurse with a long list of things I might like to learn, and in a swirl of curiosity and nervousness, I proceeded to give myself the space to take on Recurse Center’s core directive of becoming a dramatically better programmer.
Archives and AI
I found at Recurse a community of highly motivated and brilliant technologists, all of us excited to pursue projects beyond the constraints of professional employment, and to learn something about ourselves in the process. Like many others, AI was on my bingo board of potential areas of exploration, and I decided to join up with a study group around the fundamentals of machine learning. We took Andrej Karpathy’s video series on neural nets as our curriculum, working our way up from the simplest neural net to a transformer model, based on the landmark Attention is All You Need paper. The emergent behavior from simple mechanics of back-propagation and stochastic gradient descent fascinated me, as did the expressiveness of entropy introduced through techniques like batch normalization. I was reminded of my earlier years, studying physics and working in a research lab, when I first encountered model systems as an engine for advancing scientific understanding. A successful model system balances generality and specificity, such that it expresses an underlying broader truth without including all the complexity of the real world.
But also, as the neuropsychiatrist and philosopher Iain McGilchrist writes, “The model we choose to use to understand something determines what we find.” The questions of “what we find“ is partially addressed by research around AI Safety and Alignment, but the discourse around what we are looking for in AI models is much more diffuse. I sometimes think about how much of Ray Kurzweil’s pioneering research into music and AI seems to point back to the death of his father, and how themes of mortality and history commonly reappear in topics like existential risk from AI and the cultivation of data to be used in model training. With these questions in mind, I found my attention wandering from AI towards archives, which now live a double life as training sets for ML models.
In our age of planetary-scale existential precarity, archives seem to have come into a kind of fashion, offering a degree of solace in feeling knowable, static, and grounding. The training procedures of AI foundation models like GPT have a close relationship with archives too, but instead rely on their accessibility, volume, and givenness, which allows archives to be composed and instrumentalized as training sets. Abstractions of archives and AI are not impermeable, however, and as I began building my transformer model, I decided to take a broad approach to my introduction to machine learning. I began to construct an archive alongside the model, in order to see how the project might evolve through the accumulation of design decisions regarding the archive and the mechanics of the machine learning model.

In Everest Pipkin’s Corpora as medium talk, they describe the construction of a training set for machine learning as an act of curation, and remind us that curation comes from the Latin word for care, cura. More than conveying the old adage garbage in garbage out, I take this as an insight about the aura of provenance in the age of synthetic media. Critiques of generative AI as “Bach Faucets” seem to give undue priority to the sui generis quality of a work, and not enough weight to its ability to speak to (for) a corpus. Instead, my sense is that AI will increasingly take on the quality of an archive (either institutional or personal), as its oracle, in which the artifacts it generates will articulate something that is confusingly at once generative and derivative.
Prior to my professional career as a software engineer, I wrote music software for myself, programming in C++ for Arduino to control electronic music instruments. Combining software development with sound art has been a continuous thread for me throughout the intervening decade, with projects like HOBO UFO, Weaving Music, and most recently, Frog Chorus. Computer music pioneer John Bischoff once wrote about Software as Sculpture, and this feels rather resonant to me, that writing software is not as linear as it sometimes sounds, and that undertaking creative software projects is about emphasizing the qualities of exploration and expression that is present in all software development. In this tradition, I found myself looking to music on the early web as a focal point for developing the archive that would also serve as the training set for my ML model project, as an act of both curation and care.
Searching the future for what exists in the past
Before MP3s came to dominate how people listen to music on the internet, the sounds of the early web (and even BBS and Usenet before the world wide web) were predominantly expressed via MIDI. Its tiny file-size was accomodated by bandwidth limitations of the 1980s and 90s, and web-native support for the MIDI file format came early from browsers like Internet Explorer and Netscape Navigator.
The MIDI files collected for this project and used to train the model were once very new. In sifting through them, I’ve been searching for the feeling of technological transformation in an earlier age, how they combine the possibilties of new aesthetic experiences with the technics of producing and distributing this particular format of media. In giving a closer look to this history, I’ve hoped to uncover something playful and persistent about humanity’s drive towards technological transformation.
Of the artists who shared their MIDI work in the early years of the web, the researcher and musician John Sankey, who was once known to many as The Harpsichordist to the Internet, conveys a brief, but poignant retelling of how his MIDI recordings were appropriated by a commercial entity. His experience swayed him away from sharing work directly on the open web going forwards, a reactionary turn that perhaps presages what Venkatesh Rao has described as the cozy web and Yancey Strickler calls dark forest spaces after the emergence of monolithic Web2 platforms.
“I’m far from the first musician whose heart has been touched by Bach’s music, and I won’t be the last. I’ve played all of his harpsichord music at one time or another, and started to record it. Then a creep rubber-banded the tempi, pretended they were his and were played on a piano, legally copyrighted the results in the USA, and threatened legal action against sites that refused to carry them […] The sites that carry his files know what happened, and don’t care … I play for myself and friends now.” - John Sankey
It’s not without intended irony that I’ve included John Sankey’s MIDI performances of Bach in the training set for this model (though, I’m certainly not the first either). MIDI files from this time are highly technical objects requiring specialized hardware and software in addition to musicanship, but yet now overloaded with valences of nostalgia and kitsch. The juxtaposition of these qualties with machine learning felt necessary to me, in balancing sensibilities, and captures something about how linear technologic time presents history as a series of un-fulfilled futures.
Flowers from the past
Earlier this year, as I began a year-long personal sabbatical after my last two years as Engineering Manager overseeing the New York Magazine network of sites, I was eager to return to roots and build projects as an individual contributor again. I began by developing Frog Chorus, a single page web-app that allows mobile devices to sing to each other as if they were frogs, relying on acoustic proximity to communicate with each other instead of network protocols. It’s a playful gesture towards an internet that centralizes human sensory experience, distanced from the mimetic primacy of text and image that facilitates the network effects of large scale platforms.
Through this sabbatical period of soul-searching around my professional and personal relationship to technology, I’ve felt an urgency towards the poetic capacity of the internet, of the kinds of projects covered by Naive Weekly, The HTML Review, and The School for Poetic Computation. At the threshold of what feels like a new technological epoch, I felt it necessary to revisit the energy that had brought me to software, and the web, in the first place. Software, not as a service, but as sculpture.
On a trip to The Metropolitan Museum of Art in March 2023, I was struck by a couple paintings tucked into an alcove by the French Symbolist painter Odilon Redon (whose painting is featured as the lede image of this essay). Although he is predominantly known for his work with charcoal, I was enthralled both by his delicate use of color, and by the exhibition text, which informed me that he wrote about his own work in the following way:
“All my originality, then, consists in giving human life to unlikely creatures according to the laws of probability, while, as much as possible, putting the logic of the visible at the service of the invisible” - Odilon Redon
With its invocation of bringing to life and laws of probability, this statement feels as appropriate for the aims of AI, as the work of a painter. But what exactly is this invisible thing? Christian theology was likely not far from Redon’s mind, but I would speculate that the technologic society of today seems to be much more about routing the logic of the visible back into itself, a complete, but unfulfilling circle. Around the same time I visited Redon’s paintings, I had finished reading Iain McGilchrist’s The Master and His Emissary, a 600-page survey of Western civilization through the lens of lateralized brain function and structure (it turns out that sabbaticals are great for finishing books shaped like cement blocks). In his work, McGilchrist advocates for exactly what Redon describes, formalized instead as the analytic, logic-oriented left hemisphere of the brain serving not itself, but the right hemisphere of the brain, which integrates the logic of parts into the whole.
Both visibly and invisibly, I’m pleased to share the informal archive and machine learning model I’ve developed during this residency.
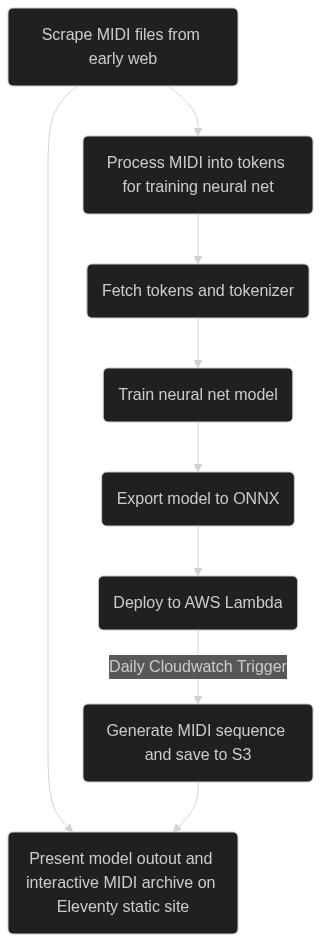
The 800k parameters decoder-only transformer model has been deployed as an AWS Lambda function, which is triggered every day around noon (GMT) to produce a few minutes of music. Each time the model is invoked, it uses tokens generated from the previous execution to produce subsequent tokens, and in this way produces a single continuous piece of music that has no end, but is punctuated by a 24-hour cycle of rest. My intent is to have the model be able to express something at once whimsical and general about the underlying archive, and serve as an entrypoint to education regarding machine learning and music on the early internet. It does not represent the state of the art in 2023, nor is it intended to be used seriously as a tool for music creation. Furthermore,the collection of files comprising the archive is small (~3000 files), and represents a diverse range of sources (Bach, pop, prog, video game soundtracks, early and medieval music, etc), such that the model is unable to develop a coherent understanding of what music actually is.
“I listened to the music. It was hideous. I have never heard anything like it. It was distorted, diabolical, without sense or meaning, except, perhaps, an alien, disconcerting meaning that should never have been there. I could believe only with the greatest effort that it had once been a Bach Fugue, part of a most orderly and respected work.” - Philip K. Dick, The Preserving Machine
As I was developing this project, I got an insightful suggestion from my friend Laurel to check out Philip K Dick’s short story, The Preserving Machine, in which living machines are produced to preserve music of the past, only to end up creating monstrosities only circumstantially connected to their original aims. I feel this rather neatly articulates the space I’ve been exploring between AI and archives, that our notions of preservation and generation are leaky abstractions. This passage also captures the spirit of the “music” produced by the model, which has a furthermore uncanny quality owing to the use of the General MIDI sound specification combined with the free improvisation energy of something like a Zeena Parkins ensemble.
I may or may not decide to further develop this project, but I hope in its current prototypal state, it manages to convey something about what drives humans to develop, use, and share technology. For more details on the implementation, check out the flow diagram below, and repositories on GitHub at https://github.com/reubenson/midi-archive and https://github.com/reubenson/midi-archive-neural-net.
And if you’re a technologist and any of this sparks inspiration to make time for realigning your relationship to software and technology, consider applying to Recurse Center to participate in an upcoming batch!